What is ElasticSearch
先搬一个官网的定义。
Elasticsearch is a real-time, distributed storage, search, and analytics engine
Elasticsearch 是一个实时的分布式存储、搜索、分析的引擎。
要想了解它是什么,首先得看他能干什么,概念很清晰: 分布式存储/搜索/分析引擎。
- 看这些概念,咋一看,数据库也都可以做到。
- 分布式存储 - 数据库也可以有主从集群模式
- 搜索 - 数据库也可以用like %% 来查找
的确,这样做的确可以, mysql也支持全文检索。但是有个问题: like %% 是不走索引的,这就意味着: 数据量非常大的时候,我们的查询肯定是秒级的。
- 我还想提一个概念: 全文检索
类似搜索引擎,输入往往是多种多样的,不同的人有不同的表达方式,但实际 都是一个含义,数据库的准确性不高,效率低下,高并发下,数据库会被拖垮。
ElasticSearch 是专门做搜索的,就是为了在理解用户输入语义并高效搜索匹配度高的文档记录。
Elasticsearch基本概念
- 近实时(NRT)
ElasticSearch是基于Lucene库的,Lucene数据只有刷新到磁盘,才可以被检索到,内存缓存中的数据只有刷新到磁盘才可以被检索。ElasticSearch默认是每秒刷新一次,也就是文档的变化会在一秒之后可见。因此近实时搜索。也可根据自己的需求设置刷新频率。
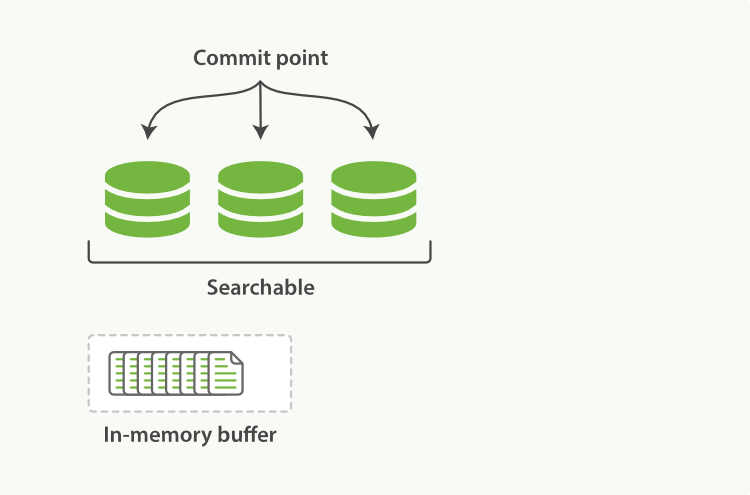
- 集群(Cluster)
海量数据单机无法存储,就需要使用集群,将多个节点组织在一起,共同维护所有数据,共同提供索引和搜索功能。
- 节点(node)
一个节点就是集群中的一个服务器,存储部分数据,参与索引与搜索。
- 分片(shards & replicas)
一个索引可以存储超出单个结点硬件限制的大量数据,为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。为保证单点故障,一个分片会保存不止一份,可分为一个**主分片(primary shard)与多个复制分片(replica shard) **,复制分片的数量可动态调整,复制分片也可用来提升系统 的读性能。
- 文档(Document)
一个文档是一个可被索引的基础信息单元。文档以JSON(Javascript Object Notation)格式来表示。
- 索引(index)
一个索引就是一个拥有几分相似特征的文档的集合。
- 索引类型(type)
索引类型是在一个索引中,不同类型的数据类型。一条文档中有(type)字段用来区分索引类型,es7.x以上取消同一个索引中存在不同索引类型的数据,也就是说,(_type)字段固定,默认为_doc。
如下,在7.x之前的ES可以在一个索引中创建不同索引类型的数据:
1 | curl -XPOST localhost:9200/indexname/typename -H 'Content-Type:application/json' -d '{"data": 1234}' |
ElasticSearch RestFul API
ES对外提供RestFul API来读写集群,设置集群,获取集群状态操作。
集群状态API
集群状态
GET /_cluster/health
1 | curl http://localhost:9200/_cluster/health --user xx:xxxx |
- 集群节点列表
1 | curl http://localhost:9200/_cat/nodes?v --user xxx:xxxx |
- 集群健康状态
结果与_cluster/health一致
1 | curl --user elastic:4j243cNvO1770iCs http://10.1.1.45:9200/_cat/health?v |
- 节点分配资源状态
1 | curl --user elastic:4j243cNvO1770iCs http://10.1.1.45:9200/_cat/allocation?v |
索引文档操作
- 索引列表
1 | curl http://localhost:9200/_cat/indices?pretty --user xx:xxxx |
- 查看索引的设置
1 | curl http://localhost:9200/[index_name]/_settings |
- 查看索引映射
1 | curl http://localhost:9200/[index_name]/_mapping --user xx:xxx |
- 创建索引
1 | curl -H "Content-Type: application/json" -XPUT localhost:9200/blogs -d ' |
- 主分片在索引创建以后就固定了,不可更改,如要修改可重建索引,将数据reindex过去;
- 副本分片最大值是 n-1(n为节点个数),复制分片可随时修改个数
2
3
4
{
"number_of_replicas": 2
}'
- reIndex操作
1 | curl -H "Content-Type: application/json" -XPOST localhost:9200/_reindex -d ' |
- 删除索引
1 | curl -H "Content-Type: application/json" -XDELETE localhost:9200/[indexname] |
查询文档操作
1 | POST http://localhost:9200/indexname/_search |
- 查看所有
1 | curl -XPOST http://localhost:9200/indexname/_search -H "Content-Type:application/json" -d '{"query":{"match_all":{} } }' |
- 精确匹配(price=549的数据)
1 | curl -XPOST http://localhost:9200/indexname/_search -H "Content-Type:application/json" -d '{"query":{"constant_score":{"filter":{"term":{"price":549} } } } }' |
- term query(title=”java”)
1 | curl -XPOST http://localhost:9200/indexname/_search -H "Content-Type:application/json" -d '{"query":{"term":{"title":"java"} } }' |
- 分词查询
1 | curl -XPOST http://localhost:9200/indexname/_search -H "Content-Type:application/json" -d '{"query":{"match":{"title":"Core Java"} } }' |
- 分词查询(全匹配)
1 | curl -XPOST http://localhost:9200/indexname/_search -H "Content-Type:application/json" -d |
索引模板
- dynamic template
1 | "dynamic_templates": [ |
- match_mapping_type
1 | put myIndex |
- match and unmatch
match和unmatch定义应用于filedname的pattern。
定义一个匹配所有以long_开头且不以_text结束的string类型的模板
1 | PUT my_index |
- example
1 | curl -XPOST http://10.1.1.12:9200/_template/default@template --user elastic:b6fBNAapGEcYz2dt -H "Content-Type:application/json" -d '{ |
快照
1 | # register a snapshot repository |
location:my_fs_backup_location 路径必须先在elasticsearch.yaml中配置path.repo
1 | path.repo: /opt/backup_es |
location |
Location of the snapshots. Mandatory. |
compress |
Turns on compression of the snapshot files. Compression is applied only to metadata files (index mapping and settings). Data files are not compressed. Defaults to true. |
chunk_size |
Big files can be broken down into chunks during snapshotting if needed. Specify the chunk size as a value and unit, for example: 1GB, 10MB, 5KB, 500B. Defaults to null (unlimited chunk size). |
max_restore_bytes_per_sec |
Throttles per node restore rate. Defaults to 40mb per second. |
max_snapshot_bytes_per_sec |
Throttles per node snapshot rate. Defaults to 40mb per second. |
readonly |
Makes repository read-only. Defaults to false. |
快照策略
SLM
elastic设置密码
elasticsearch.yml增加如下配置
1 | xpack.security.enabled: true |
重新启动es, 执行
1 | bin/elasticsearch-setup-passwords interactive |
这里需要为4个用户分别设置密码,elastic, kibana, logstash_system,beats_system,交互输入密码。
修改密码:
1 | curl -H "Content-Type:application/json" -XPOST -u elastic 'http://127.0.0.1:9200/_xpack/security/user/elastic/_password' -d '{ "password" : "123456" }' |
索引选项
index.refresh_interval
数据索引后并不会马上搜索到,需要刷新后才能被搜索的,这个选项设置索引后多久会被搜索到。
index.translog
- sync_interval
- durability
Why yellow
- 多数据节点故障
- 为索引使用损坏的或红色的分区
- 高 JVM 内存压力或 CPU 利用率
- 磁盘空间不足
Fix yellow
- 列出未分配的分区
1 | curl -XGET 'localhost:9200/_cat/shards?h=index,shard,prirep,state,unassigned.reason' | grep UNASSIGNED |
输出:
1 | xxxxx 0 r UNASSIGNED INDEX_CREATED |
展示出所有未分配的分片的列表
- 检索为什么未分配
1 | curl -XGET 'localhost:9200/_cluster/allocation/explain?pretty' -H 'Content-Type:application/json' -d'{"index": "xxxxx", "shard": 0, "primary":false}' |
输出:(未记录输出)
会给出集群中所有节点不能分配的原因。
- 解决
如果是磁盘空间不足,删除不必要的索引。对于其他原因,可根据情况解决不能分配的原因。比如下面几个常见的原因。
a. cluster.max_shards_per_node默认为1000,节点分片已经达到最大。
b. 磁盘空间达到配置的阈值,比如磁盘已经达到80%,不会继续分配分片。
c. 分片设置的节点必须是hot节点。
可通过如下接口查看当前磁盘分配配置:
1 | curl -XGET _cluster/settings?include_defaults=true&flat_settings=true&pretty |
输出(输出太多截取一部分):
1 | { |
索引生存周期(ILM)
适用于单索引并不断增长,可设置ILM rollover,根据大小或者文档条数拆分.
对于按天索引,可配置删除阶段规则.
创建ILM策略(hot/warm/cold/delete)
创建索引模板,指定ILM的范围
创建rollover的索引,名称末尾要是数字,这样rollover就会+1, 如:carlshi-00001;配置is_write_index选项
原索引写入数据
For Example:
1 | 创建索引模板 |
创建索引:
1 | 创建第一个索引 |
elasticsearch docker
直接运行elasticsearch,会自动拉去镜像并执行;
1 | docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.5.1 -v /usr/share/elasticsearch/data:/usr/share/elasticsearch/data |
运行成功后,执行curl,获取基本信息
1 | curl localhost:9200 |
小结
ElasticSearch是一款强大的全文检索工具,他提供REST API使得使用ElasticSearch非常简单,对数据做了很强的高可用,也可根据自己的需求配置不同级别的高可用、高性能全文检索工具。
本篇主要讲解对ElasticSearch的常用模块做了简单的介绍,索引的基本属性基本操作(增删改查),动态索引模式模板,快照备份,索引生存周期;还记录了集群黄色的排查方向。以后逐步深入各个模块的配置甚至内部实现原理。